
Rongjie Huang (黄融杰) is at Seamless Team at FAIR. Previously, I graduated from College of Computer Science, Zhejiang University, supervised by Prof. Zhou Zhao. I also obtained Bachelor’s degree at Zhejiang University. My research interest includes Multi-modal Large Language Model, Video-Audio Generative Models, and Audio-Visual Language Processing. I have published first-author papers at the top international AI conferences such as NeurIPS/ICLR/ICML/ACL/IJCAI. I developed a few well-known Speech/NLP algorithms including:
- Multimodal LLMs: Seamless-Interaction (LLama4+Dyadic Motion Diffusion), AudioGPT, UniAudio, Make-A-Voice
- Omini-modal Audio Generative Models: Lumina-T2X (omini-modal), Make-An-Audio, Make-An-Audio-2, FastDiff, GenerSpeech
- Multimodal Translation: TranSpeech, and AV-TranSpeech
🔥 News
- 2025.04: I am awarded the Best Thesis Award by the Electrical Engineering Association!
- 2025.02: 4 papers are accepted by ICLR 2025!
- 2025.01: 1 paper is accepted by AAAI 2025!
- 2024.10: 6 papers are accepted by NeurIPS 2024!
- 2024.05: 6 papers are accepted by ACL 2024! (main conference and findings)!
- 2024.05: 3 papers are accepted by ICML 2024!
- 2024.03: 1 paper is accepted by NAACL 2024 main conference!
- 2024.01: 1 paper is accepted by ICLR 2024!
- 2023.11: 2 papers are accepted by AAAI 2024 main / AAAI 2024 demo!
- 2023.10: I am awarded ByteDance Scholar Fellowship, and Chu Kochen Presidential Scholarship!
- 2023.10: UniAudio released!
- 2023.09: One paper is accepted by EMNLP 2023!
- 2023.07: One paper is accepted by ACM-MM 2023!
- 2023.06: One paper is accepted by ICCV 2023!
- 2023.05: 8 papers are accepted by ACL 2023 (main conference and findings)! Thanks to my co-authors!
- 2023.04: AudioGPT and HiFi-Codec released!
- 2023.04: One papers is accepted by ICML 2023!
- 2023.02: Make-An-Audio released! Media coverage: Heart of Machine, ByteDance and Twitter
- 2023.01: One papers is accepted by ICLR 2023!
- 2022.09: Two papers are accepted by NeurIPS 2022!
📝 Representative Publications
Multi-modal Large Language Model
- Speech Pre-training: InstructSpeech (ICML, 2024), UniAudio (ICML, 2024)
- Joint understanding and generation: Seamless Interaction (Technical Report, 2025), AudioGPT (AAAI, 2024)
- Efficient Post-training: MVoice (ACL, 2024), VoiceTuner (ACM-MM, 2024)
Omini Audio Generative Models
- Video-to-Audio Generation: Lumina-T2X (ICLR 2025), Make-An-Audio (ICML 2023)
- Speech Generation: GenerSpeech (NeurIPS, 2022), FastDiff (IJCAI, 2022), ProDiff (ACM-MM, 2022), FastDiff 2 (ACL, 2023)
- Music Generation: SingGAN (ACM-MM, 2022), Multi-Singer (ACM-MM, 2021)
Audio-Visual Language Processing
- Speech Translation: TranSpeech (ICLR, 2023), AV-TranSpeech (ACL, 2023)
- Self-Supervised Learning: Prosody-MAE (ACL, 2023)

TLDR: Llama 4 with speech-text interleaved to generate duplex audio, and diffusion model to generate dyadic motion gestures and facial expressions aligned with human speech.
We develop a suite of joint LLM and diffusion models (AVLM) to generate dyadic motion gestures and facial expressions aligned with human speech. The AVLM can understand and generate both speech and visual modalities. With 2D and 3D renderers, it brings us closer to interactive virtual agents. Our work are promoted by different media and forums, such as Meta AI, Linkedin, and Twitter. We have code released at 
download has yielded 30k+.
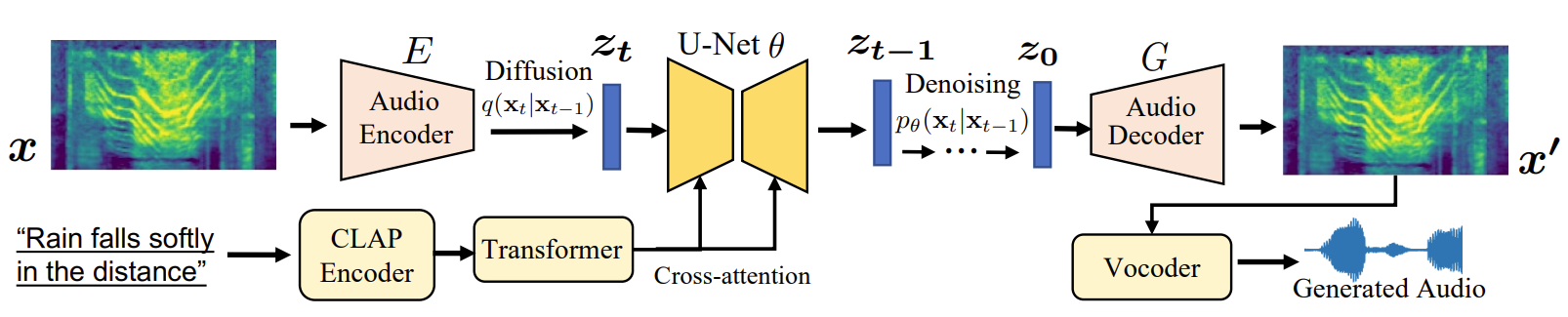
-
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head. Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shinji Watanabe. AAAI, 2024
-
Academic / Industry Impact: Our work are promoted by different media and forums, such as Heart of Machine, New Intelligence, and Twitter. We have code released at
.

-
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models. Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, Zhou Zhao. ICML, 2023. Hawaii, USA
-
Academic / Industry Impact: Our work are promoted by different media and forums, such as Heart of Machine, ByteDance, and Twitter. Code is coming!
- TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation. Rongjie Huang, Jinglin Liu, Huadai Liu, Yi Ren, Lichao Zhang, Jinzheng He, and Zhou Zhao. ICLR, 2023. Kigali, Rwanda
One of our continuous efforts to reduce communication barrier, and we have follow-up works: Audio-Visual S2T (MixSpeech, ICCV 2023), Audio-Visual S2ST (AV-TranSpeech, ACL 2023), Multi-modal S2ST, Style-aware S2ST, Zero-shot S2ST. Code released: .
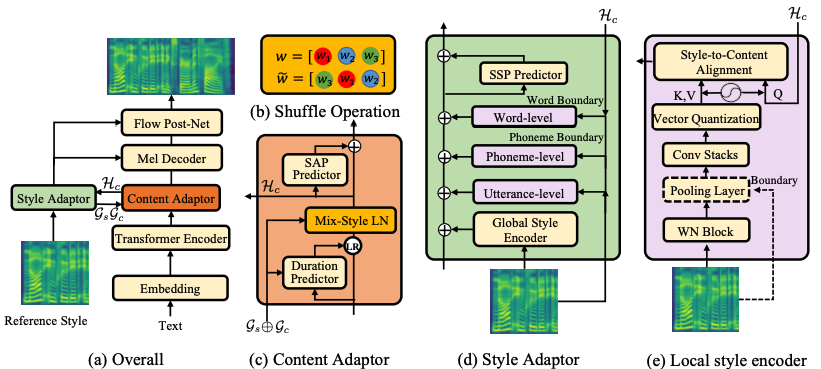
- GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech. Rongjie Huang, Yi Ren, Jinglin Liu, Chenye Cui, and Zhou Zhao. NeurIPS, 2022. New Orleans, USA
The first zero-shot TTS generalizable to unseen speaker, emotion, and prosody! Media coverage: PaperWeekly, Speech Home. Code released: 
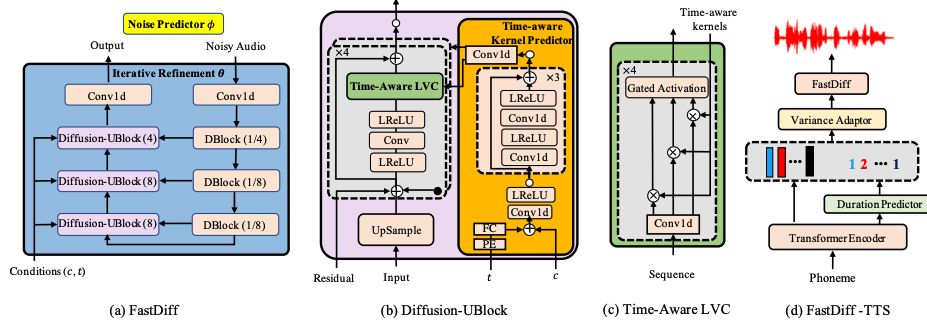
- FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis. Rongjie Huang, Max W.Y. Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, and Zhou Zhao. IJCAI, 2022(oral). Vienna, Austria
One of our continuous efforts in generative modeling, and we have follow-up works: FastDiff 2, ProDiff. We release a diffusion text-to-speech pipeline using ProDiff


Full Publication List
- denotes co-first authors, # denotes co-supervised
2025
-
OmniSep: Unified Omni-modal Sound Separation. Xize Cheng, Zehan Wang, Ziang Zhang, Rongjie Huang, Jialung Zuo, Shengpeng Ji, Ziyang Ma, Siqi Zheng, Tao Jin, Zhou Zhao. ICLR, 2025
-
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers. Peng Gao, Le Zhuo, Dongyang Liu, Ruoyi Du, Xu Luo, Longtian Qiu, Yuhang Zhang, Rongjie Huang, Shijie Geng, Renrui Zhang, Junlin Xie, Wenqi Shao, Zhengkai Jiang, Tianshuo Yang, Weicai Ye. ICLR, 2025
-
GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation. Zhenhui Ye, Jinzheng He, Ziyue Jiang, Rongjie Huang, Jiawei Huang, Jinglin Liu, Yi Ren, Xiang Yin, Zejun MA, Zhou Zhao. ICLR, 2025
-
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling. Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, Ziang Zhang, Xiaoda Yang, Rongjie Huang, Yidi Jiang, Qian Chen. ICLR, 2025
-
Improving Multi-modal Representations via Binding Space in Scale. Zehan Wang, Ziang Zhang, Minjie Hong, Hang Zhang, Luping Liu, Rongjie Huang, Xize Cheng, Shengpeng Ji, Tao Jin, Hengshuang Zhao, Zhou Zhao. ICLR, 2025
-
VoxDialogue: Can Spoken Dialogue Systems Understand Information Beyond Words? Xize Cheng, Ruofan Hu, Xiaoda Yang, Jingyu Lu, Dongjie Fu, Zehan Wang, Shengpeng Ji, Rongjie Huang, Boyang Zhang, Tao Jin, Zhou Zhao. ICLR, 2025
-
TechSinger: Technique Controllable Multilingual Singing Voice Synthesis via Flow Matching. Wenxiang Guo, Yu Zhang, Changhao Pan, Rongjie Huang, Li Tang, Ruiqi Li, Zhiqing Hong, Yongqi Wang, Zhou Zhao. AAAI, 2025
-
3D-Speaker-Toolkit: An Open-Source Toolkit for Multimodal Speaker Verification and Diarization. Yafeng Chen, Siqi Zheng, Hui Wang, Rongjie Huang, Qian Chen, Shiliang Zhang, Wen Wang, Xihao Li. ICASSP, 2025
-
NAT3DSound: 3D Spatial Sound Field Synthesis with Multi-Modal Non-Autoregressive Transformer. Fuming You, Rongjie Huang, Boyang Zhang, Yongqi Wang, Zhiqing Hong, Qian Yang, Zhimeng Zhang, Zhou Zhao. ICASSP, 2025
2024
-
InstructSpeech: Following Speech Editing Instructions via Large Language Models. Rongjie Huang, Ruofan Hu, Yongqi Wang, Zehan Wang, Xize Cheng, Ziyue Jiang, Zhenhui Ye, Dongchao Yang, Luping Liu, Peng Gao, Zhou Zhao. ICML, 2024.
-
Make-A-Voice: Multilingual Unified Voice Generation With Discrete Representation at Scale. Rongjie Huang, Chunlei Zhang, Yongqi Wang, Dongchao Yang, Jinchuan Tian, Luping Liu, Zhenhui Ye, Ziyue Jiang, Xuankai Chang, Jiatong Shi, Chao Weng, Zhou Zhao, Dong Yu. ACL, 2024.
-
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head. Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shinji Watanabe. AAAI demo, 2024
-
UniAudio: An Audio Foundation Model Toward Universal Audio Generation. Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Xixin Wu, Zhou Zhao, Shinji Watanabe, Helen M. Meng. ICML, 2024.
-
Molecule-Space: Free Lunch in Unified Multimodal Space via Knowledge Fusion. Zehan Wang, Ziang Zhang, Xize Cheng, Rongjie Huang, Luping Liu, Zhenhui Ye, Haifeng Huang, Yang Zhao, Tao Jin, Peng Gao, Zhou Zhao. ICML, 2024.
-
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt. Dongchao Yang, Songxiang Liu, Rongjie Huang, Guangzhi Lei, Chao Weng, Helen Meng, Dong Yu. IEEE Transactions on Acoustics, Speech, and Signal Processing.
-
Robust Singing Voice Transcription Serves Synthesis. Ruiqi Li, Yu Zhang, Yongqi Wang, Zhiqing Hong, Rongjie Huang, Zhou Zhao. ACL, 2024.
-
Text-to-Song: Towards Controllable Music Generation Incorporating Vocal and Accompaniment. Zhiqing Hong, Rongjie Huang, Xize Cheng, Yongqi Wang, Ruiqi Li, Fuming You, Zhou Zhao, Zhimeng Zhang. ACL, 2024.
-
TransFace: Unit-Based Audio-Visual Speech Synthesizer for Talking Head Translation. Xize Cheng, Rongjie Huang, Linjun Li, Tao Jin, Zehan Wang, Aoxiong Yin, Minglei Li, Xinyu Duan, changpeng yang, Zhou Zhao. ACL finding, 2024.
-
Wav2SQL: Direct Generalizable Speech-To-SQL Parsing. Huadai Liu, Rongjie Huang, Jinzheng He, Ran Shen, Gang Sun, Xize Cheng and Zhou Zhao. ACL finding, 2024.
-
Self-Supervised Singing Voice Pre-Training towards Speech-to-Singing Conversion. Ruiqi Li, Rongjie Huang, Yongqi Wang, Zhiqing Hong, Zhou Zhao. ACL finding, 2024.
-
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis. Zhenhui Ye, Tianyun Zhong, Yi Ren, Jiaqi Yang, Weichuang Li, Jiawei Huang, Ziyue Jiang, Jinzheng He, Rongjie Huang, Jinglin Liu, Chen Zhang, Xiang Yin, Zejun MA, Zhou Zhao. ICLR, 2024.
-
StyleSinger: Style Transfer for Out-Of-Domain Singing Voice Synthesis. Yu Zhang#, Rongjie Huang, Ruiqi Li, Jinzheng He, Yan Xia, Feiyang Chen, Xinyu Duan, Baoxing Huai, Zhou Zhao. AAAI, 2024.
-
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt Yongqi Wang#, Ruofan Hu#, Rongjie Huang, Zhiqing Hong, Ruiqi Li, Wenrui Liu, Fuming You, Tao Jin, Zhou Zhao. NAACL, 2024.
-
EchoAudio: Efficient and High-Quality Text-to-Audio Generation with Minimal Inference Steps Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao. ACMMM, 2024.
2023
-
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models. Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, Zhou Zhao. ICML, 2023. Hawaii, USA
-
Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias. Ziyue Jiang, Yi Ren, Zhenhui Ye, Jinglin Liu, Chen Zhang, Qian Yang, Shengpeng Ji, Rongjie Huang, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao. Arxiv
-
Make-An-Audio 2: Improving Text-to-Audio with Dual Text Information Representation. Jiawei Huang#, Yi Ren, Rongjie Huang, Dongchao Yang, Zhenhui Ye, Chen Zhang, Jinglin Liu, Xiang Yin, Zejun Ma, Zhou Zhao. Arxiv, 2023
-
TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation. Rongjie Huang, Jinglin Liu, Huadai Liu, Yi Ren, Lichao Zhang, Jinzheng He, and Zhou Zhao. ICLR, 2023. Kigali, Rwanda
-
AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation. Rongjie Huang, Huadai Liu, Xize Cheng, Yi Ren, Linjun Li, Zhenhui Ye, Jinzheng He, Lichao Zhang, Jinglin Liu, Xiang Yin and Zhou Zhao. ACL, 2023
-
MixSpeech: Cross-Modality Self-Learning with Audio-Visual Stream Mixup for Visual Speech Translation and Recognition. Xize Cheng, Linjun Li, Tao Jin, Rongjie Huang, Wang Lin, Zehan Wang, Huangdai Liu, Ye Wang, Aoxiong Yin, Zhou Zhao. ICCV, 2023
-
CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-Training. Zhenhui Ye*, Rongjie Huang, Yi Ren, Ziyue Jiang, Jinglin Liu, Jinzheng He, Xiang Yin and Zhou Zhao. ACL, 2023
-
UniSinger: Unified End-to-End Singing Voice Synthesis With Cross-Modality Information Matching. Zhiqing Hong#, Chenye Cui, Rongjie Huang, Lichao Zhang, Jinglin Liu, Jinzheng He, Zhou Zhao. ACM MM, 2023
-
AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment. Ruiqi Li#, Rongjie Huang, Lichao Zhang, Jinglin Liu, Zhou Zhao. ACL finding, 2023
-
RMSSinger: Realistic-Music-Score based Singing Voice Synthesis. Jinzheng He, Jinglin Liu, Zhenhui Ye, Rongjie Huang, Chenye Cui, Huadai Liu, Zhou Zhao. ACL finding, 2023
-
FluentSpeech: Stutter-Oriented Automatic Speech Editing with Context-Aware Diffusion Models. Ziyue Jiang, Qian Yang, Jialong Zuo, Zhenhui Ye, Rongjie Huang, Yi Ren, Zhou Zhao. ACL finding, 2023
-
Contrastive Token-Wise Meta-Learning for Unseen Performer Visual Temporal-Aligned Translation. Linjun Li, Tao Jin, Xize Cheng, Ye Wang, Wang Lin, Rongjie Huang, Zhou Zhao. ACL finding, 2023
-
ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer. Huadai Liu, Rongjie Huang, Xuan Lin, Wenqiang Xu, Maozong Zheng, Hong Chen, Jinzheng He, Zhou Zhao. EMNLP, 2023
2022
-
GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech. Rongjie Huang, Yi Ren, Jinglin Liu, Chenye Cui, and Zhou Zhao. NeurIPS, 2022. New Orleans, USA
-
Prosody-TTS: Self-Supervised Prosody Pretraining with Latent Diffusion For Text-to-Speech. Rongjie Huang, Chunlei Zhang, Yi Ren, Zhou Zhao, Dong Yu. ACL finding, 2023
-
FastDiff 2: Dually Incorporating GANs into Diffusion Models for High-Quality Speech Synthesis. Rongjie Huang, Yi Ren, Jinglin Liu, Luping Liu, Zhou Zhao. ACL finding, 2023
-
FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis. Rongjie Huang, Max W.Y. Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, and Zhou Zhao. IJCAI, 2022(oral). Vienna, Austria
-
ProDiff: Progressive Fast Diffusion Model for High-Quality Text-to-Speech. Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, and Yi Ren. ACM MM, 2022. Lisbon, Portugal
-
M4Singer: a Multi-Style, Multi-Singer and Musical Score Provided Mandarin Singing Corpus. Lichao Zhang, Ruiqi Li, Shoutong Wang, Liqun Deng, Jinglin Liu, Yi Ren, Jinzheng He, Rongjie Huang, Jieming Zhu, Xiao Chen, and Zhou Zhao. NeurIPS, 2022. New Orleans, USA
-
VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement. Chenye Cui, Yi Ren, Jinglin Liu, Rongjie Huang, Zhou Zhao. ICASSP, 2023
2021
-
Multi-Singer: Fast multi-singer singing voice vocoder with a large-scale corpus. Rongjie Huang, Feiyang Chen, Yi Ren, Jinglin Liu, Chenye Cui, and Zhou Zhao. ACM MM, 2021(oral). Chengdu, China | Project |
-
EMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model. Chenye Cui, Yi Ren, Jinglin Liu, Feiyang Chen, Rongjie Huang, Mei Li, and Zhou Zhao. Interspeech, 2021
-
Bilateral Denoising Diffusion Models. Max W.Y. Lam, Jun Wang, Rongjie Huang, Dan Su, Dong Yu. Preprint

2020 and Prior
- SingGAN: Generative Adversarial NetWork For High-Fidelity Singing Voice Generation. Rongjie Huang, Chenye Cui, Feiyang Chen, Yi Ren, Jinglin Liu, and Zhou Zhao. ACM MM, 2022. Lisbon, Portugal | Project
Selected Honors Awarded
- Best Thesis Award, National Electrical Engineering Association (2025).
- Excellent Graduate, Zhejiang Province (2024).
- Chu Kochen Presidential Scholarship (2023), highest honor at Zhejiang University
- ByteDance Scholar Fellowship (100k RMB Bonus), 10 students per year
- ICML/ICLR Grant Award
- Outstanding Reviewers, ICML’22. Top 10%.
- National Scholarship (2022, 2023, Grauate student). Top 1%.
- National Scholarship (2020, 2021, Undergrauate student). Top 1%.
- Excellent Graduate, Zhejiang Province (2021).
- Chu Kochen Presidential Scholarship Finalist (2021).
- First Prize in American Mathematical Modeling Competition (2020).
- First Prize of National Mathematical Modeling Competition in Zhejiang Province (2019).
Professional Services
- Conference Reviewer/Program Committee: ICML 2022, ACM-MM 2022, NeurIPS 2022, ARR 2022, ICML 2023, ARR 2023, ACL 2023, EMNLP 2023, ACM-MM 2023, NeurIPS 2023, ICLR 2023, ICML 2023, Neuralcomputing, IJCAI 2024, ACM-MM 2024, ACL 2024, TIP
- Assist to Review: KDD 2022, AAAI 2022, EMNLP 2022, PRCV 2021, TMM
